Legacy Media Data Migration Project
A data migration project: transforming multiple separate datasets of legacy media into an organised collection for archival purposes.
Adobe Flash media archival project
 Representation of before and after data migration
Representation of before and after data migration
From the early 2000s to late 2010s, Adobe Flash was a popular software platform used by web developers to create multimedia and interactive content. In 2020, support for Adobe Flash was discontinued and the ‘SWF’ format used by Adobe Flash programs became defunct. As a result, much of the content created during this era is inaccessible to consumers. This created an opportunity for a project to migrate this data to a format that is universally supported by modern computers and preserve an important part of internet history.
Using the now-defunct popular online game platform Club Penguin as an example, I set about constructing an archive of the platform’s library of music. The platform’s audio tracks were contained in Adobe Flash ‘SWF’ files, and the discontinuation of support for Adobe Flash resulted in the inability to access or play music stored in this codec.
Multiple community-run websites maintained datasets throughout the life of the platform, recording metadata about each music track released by the platform, and a copy of the SWF containing the audio. However, these datasets were maintained independently of each other, and each have data quality issues, such as missing tracks, duplicate tracks, or different titles for the same track.
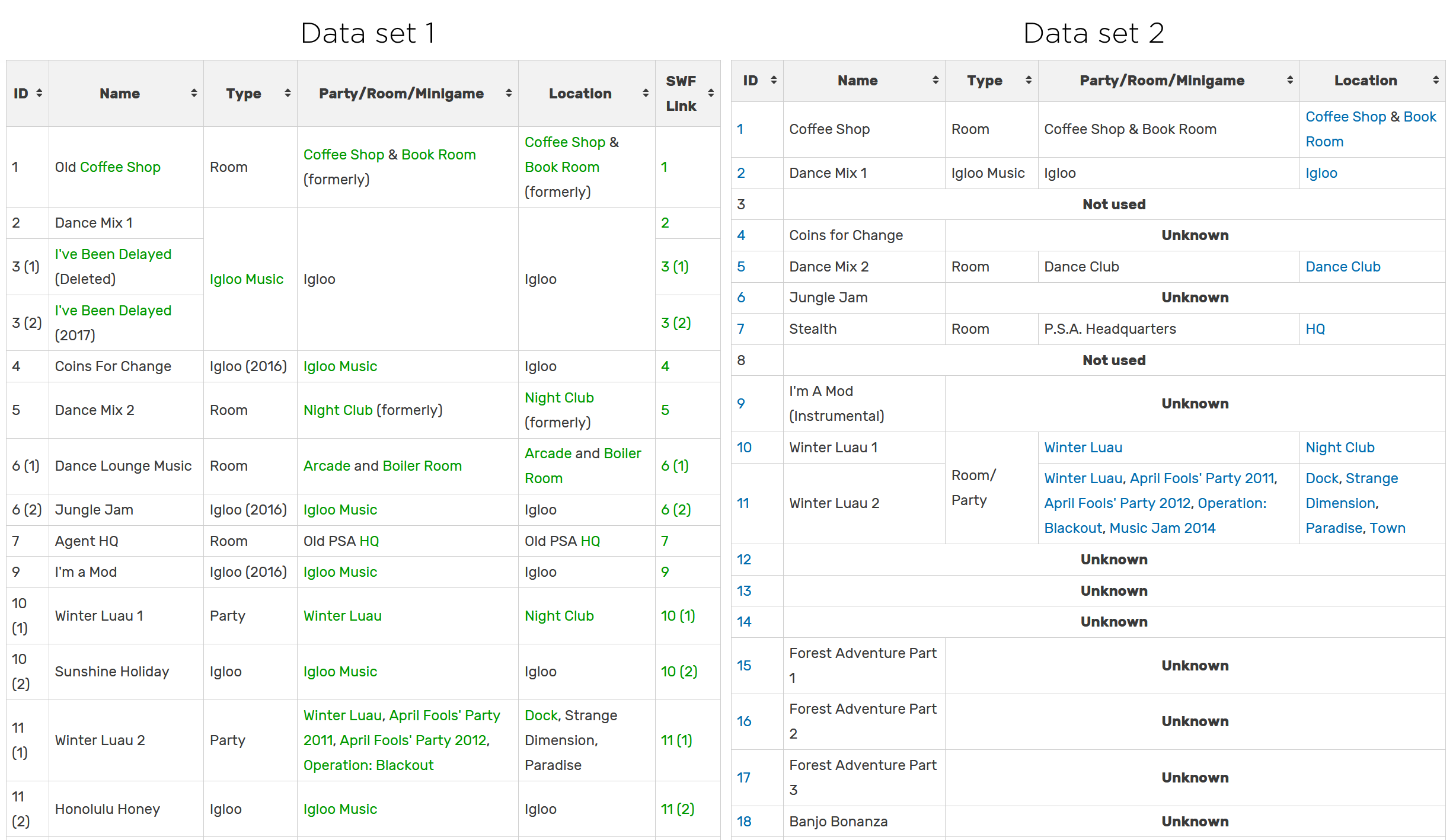 Screenshot of the initial separate datasets with inconsistencies (Excerpt)
Screenshot of the initial separate datasets with inconsistencies (Excerpt)
These datasets were web scraped, joined together, and ordered by ID in a CSV file. A Python script was written to bulk download the associated SWFs grouped by ID.
 Table of tracks grouped by ID (Excerpt)
Table of tracks grouped by ID (Excerpt)
 Local archive of SWF files grouped by ID (Excerpt)
Local archive of SWF files grouped by ID (Excerpt)
While some tracks were identical across datasets, some tracks featured multiple versions due to IDs being reused when certain tracks were replaced throughout the life of the platform.
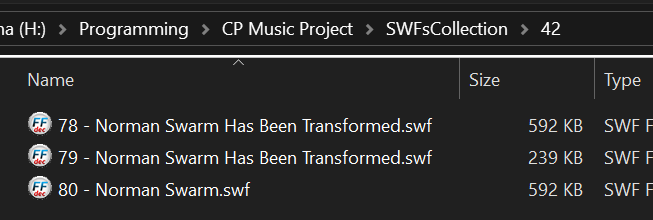
Multiple versions of a track sharing the same ID (Excerpt)
Additionally, some tracks were unnamed in either dataset, or had multiple names when the datasets were combined.
 Multiple instances of a single track, with one lacking a name (Excerpt)
Multiple instances of a single track, with one lacking a name (Excerpt)
To remove unnecessary duplicate files, a script was written to compare the hashes of all files, record the aliases of tracks, and retain only one copy of a unique file. The result was a JSON dataset of all unique tracks accompanied by their respective title(s) and track ID(s).
 A JSON file including the hashes and aliases of tracks
A JSON file including the hashes and aliases of tracks
A Python script was written to carry out OS commands and utilise the following external tools via the command line. JPEXS FFDec was used to extract the audio streams of every SWF file. Due to how the SWF codec is designed, some music tracks are split into multiple audio streams. FFmpeg was used to concatenate the separate audio streams into a single MP3 file.
![A single SWF file consisting of multiple audio streams [JPEXS FFDec GUI]](/assets/flash-project/05a-extract-mp3s-from-swfs.png)
A single SWF file consisting of multiple audio streams [JPEXS FFDec GUI]
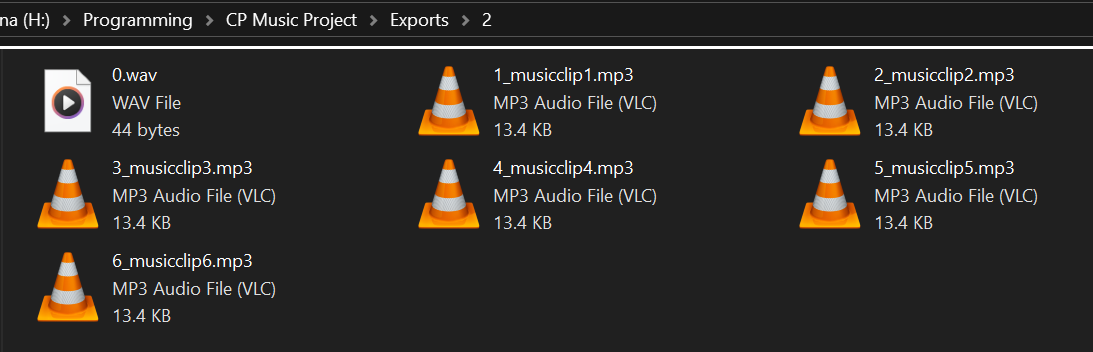 A single track split into multiple audio segments
A single track split into multiple audio segments
 A collection of unique music tracks, after duplicate files are removed and separated audio segments are concatenated (Excerpt)
A collection of unique music tracks, after duplicate files are removed and separated audio segments are concatenated (Excerpt)
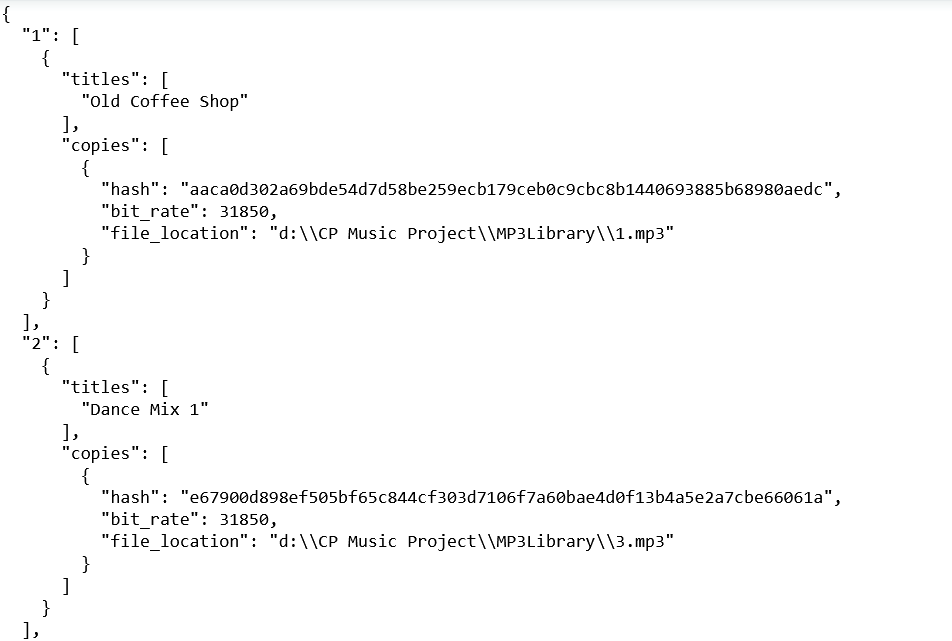 JSON dataset of the collection of unique music tracks (Excerpt)
JSON dataset of the collection of unique music tracks (Excerpt)
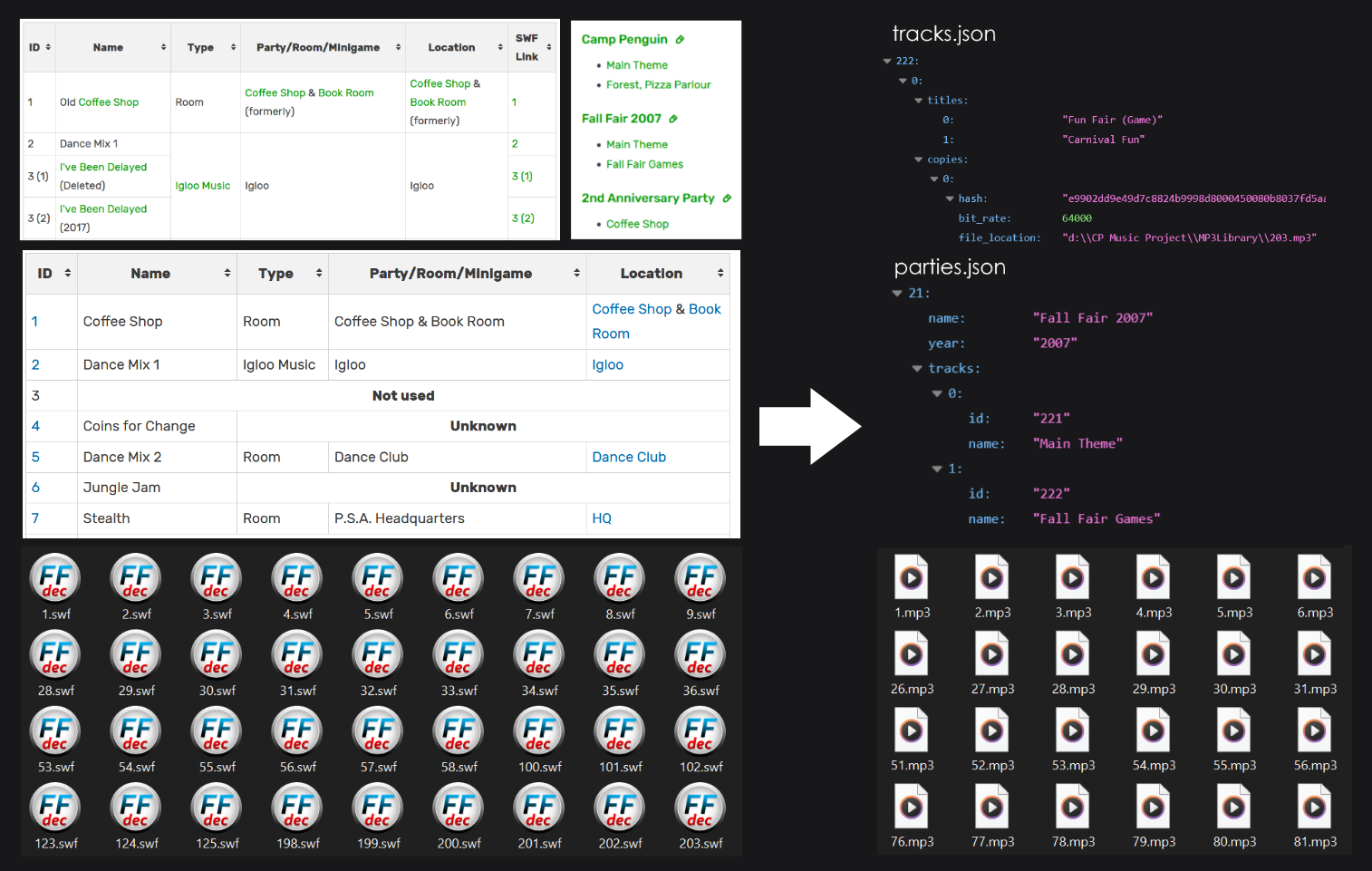
A third dataset containing information on the usage of each track was restructured into JSON. Each ‘party’ has a list of tracks used. Using the track ID, the respective audio file can be retrieved.
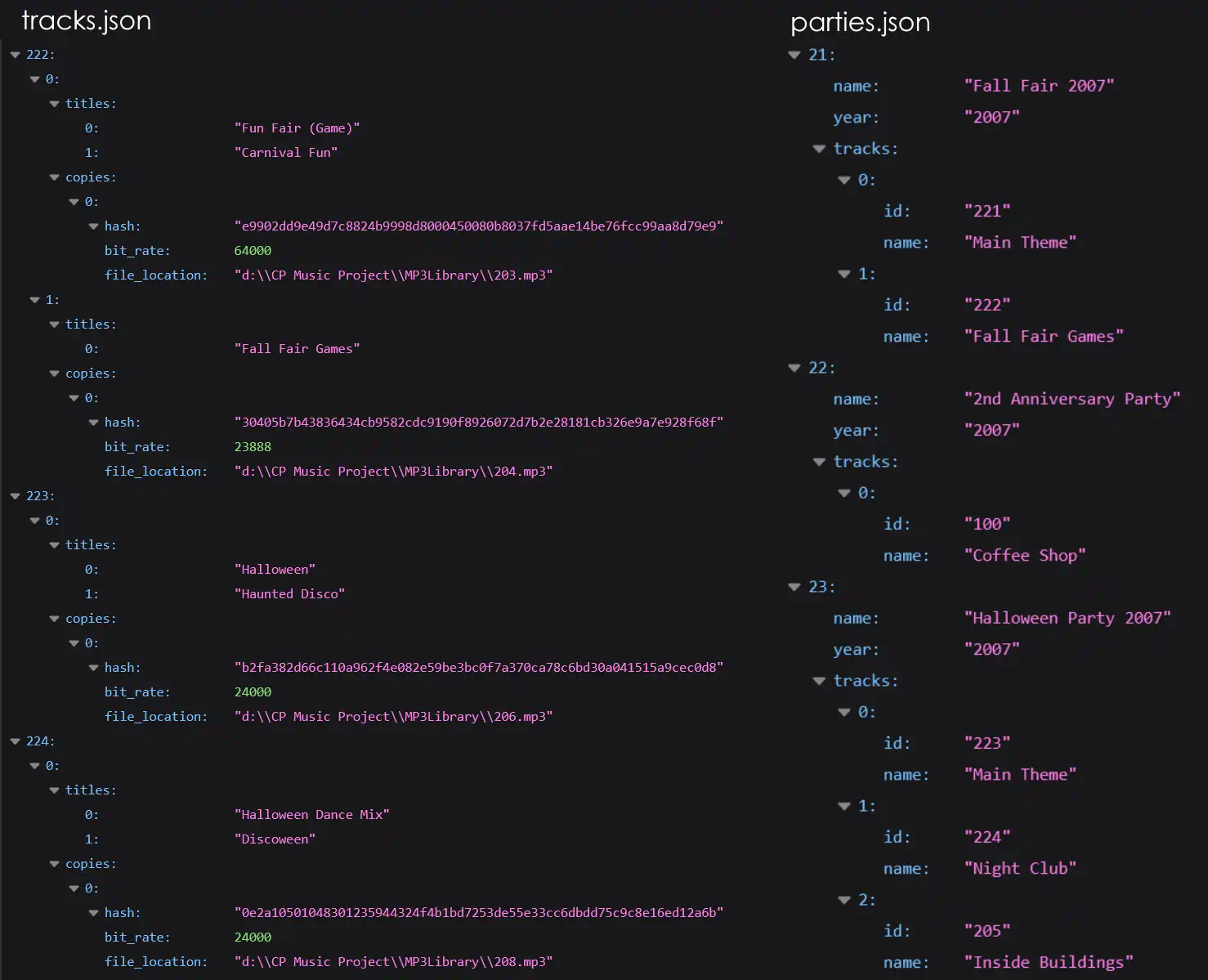 Final datasets: tracks and parties (Excerpts)
Final datasets: tracks and parties (Excerpts)
Summary
This project involved web scraping and merging incomplete datasets, and data cleaning, to produce a complete dataset of information about music tracks used by an online platform. Through writing scripts in Python and batch, utilising JPEXS FFDec and ffmpeg, an archive of Adobe Flash ‘SWF’ files was transformed into a catalogued collection of MP3s and metadata.